





EYとは、アーンスト・アンド・ヤング・グローバル・リミテッドのグローバルネットワークであり、単体、もしくは複数のメンバーファームを指し、各メンバーファームは法的に独立した組織です。アーンスト・アンド・ヤング・グローバル・リミテッドは、英国の保証有限責任会社であり、顧客サービスは提供していません。

eDiscovery対応において、訴訟への関連性がないデータを除外し不要な情報を開示しないことは、企業の訴訟戦略上、極めて重要です。また、膨大な量のデータを適切に処理できるかどうかは、eDiscoveryの結果やコストに大きく影響します。
本稿では、eDiscoveryの一連の作業の中でも特に重要なプロセスの1つであるProcessingについて、代表的な処理手法を紹介するとともに、そのリスクと重要性を解説します。
要点
- Processingは「データの処理」を指し、不要データや重複の排除、メタデータの抽出等を行い、後続の対応に適した状態に整えるプロセスである。
- 保全および収集時の電子的に保存された情報(Electronically Stored Information、以下ESIという)を未処理のまま後続のレビューや分析に移行すると、訴訟に無関係なデータが混在することで、作業時間やコストの増加、重要情報の見落とし、レビュー結果の不整合といったリスクが生じる。
- データ量のコントロールは、eDiscovery対応の結果とコストを左右する重要な要素の1つであり、Processingにおいてどのような戦略や技術を用いるかが、eDiscoveryの効率化と品質向上に直結する。
1. はじめに
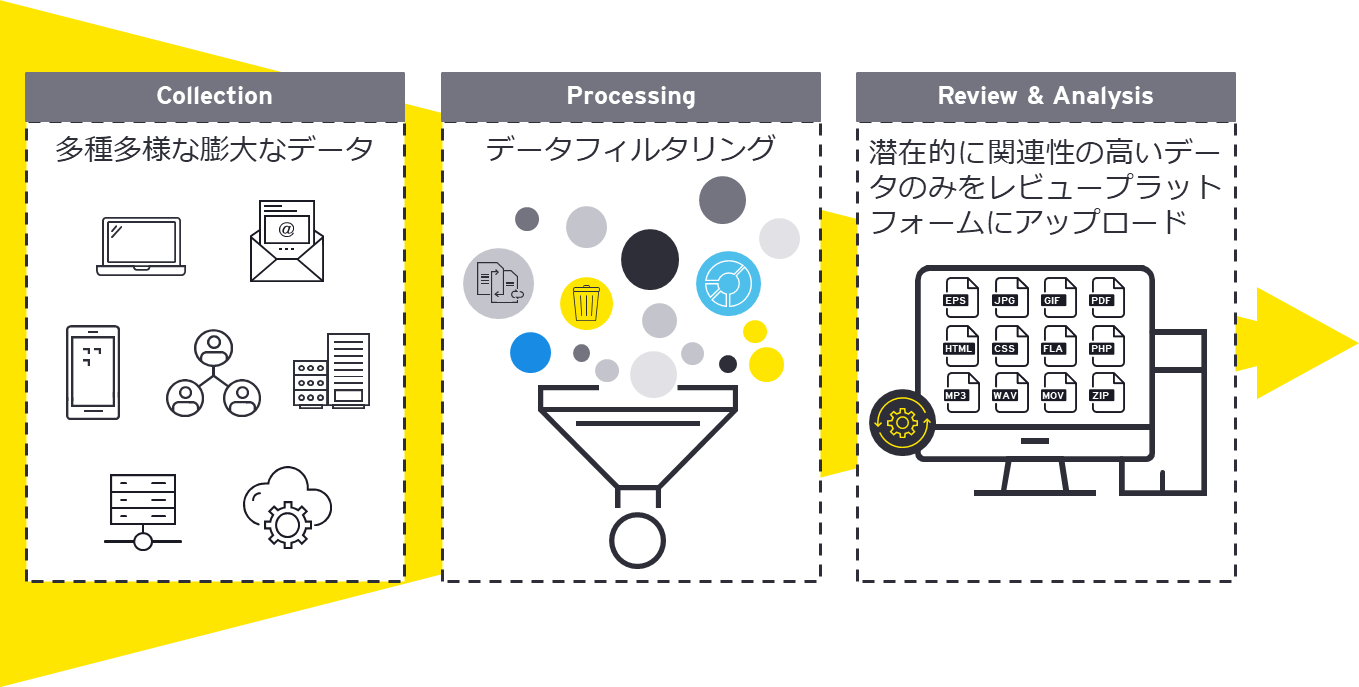
EDRM(Electronic Discovery Reference Model/電子情報開示参考モデル)※1の第三段階であるProcessing(処理)は、Preservation (保全)および Collection(収集)のプロセスで保全・収集されたESIを、後続の対応であるReview(レビュー)やAnalysis(分析)に適した状態に整えるプロセスです。
近年、ビジネスコミュニケーションのデジタル化が加速し、企業が取り扱うESIの量と種類は飛躍的に増加しています。2006年FRCP(Federal Rules of Civil Procedure:連邦民事訴訟規則)改正により電子情報が正式に開示対象と認められて以降、法的紛争や調査においてESIが重要な証拠となるケースが急増しています。
このような状況の中で、Processingは単なる前処理にとどまらず、膨大なデータの中から関連性の高い情報を効率的に抽出・整理し、eDiscovery全体の品質と効率を左右する重要なプロセスであると考えられています。
本稿では、Processingの代表的な処理手法と重要性について解説します。
※1 EDRMは「Electronic Discovery Reference Model」の略で、電子情報開示制度を概念化したモデルです。法的な紛争や調査の際に、電子的な形式で保存されている情報(電子情報)を適切に管理し開示するための一連のステップを定義しています。
参考:eDiscoveryとEDRM ― 米国民事訴訟における証拠開示制度
2. eDiscoveryにおけるProcessingの重要性
保全・収集されたESIは、多くの場合、その段階ではレビューや分析に適した状態ではありません。例えば、ZIPやPSTのようなコンテナファイル、暗号化されたファイル、スキャンされたPDFなどの画像ファイルは、コンテナ化や暗号化により内部ファイルを確認ができなかったり、文字情報を取得できなかったりするため、レビュープラットフォーム上での検索が困難になります。また、システムファイルやキャッシュファイルなど、調査や訴訟に明らかに無関係なデータが大量に混在しているケースも少なくありません。
このようなデータを未処理のまま後続のプロセスであるレビューや分析へ移行すると、作業時間やコストが大幅に増加するだけでなく、重要情報の見落としやレビュー結果の不整合といったリスクを招く恐れがあります。
Processingでは、こうした課題に対処するために主に以下のような処理が行われます:
- 不要なデータの排除
- データ展開処理
- 重複排除(Deduplication)
- テキストやメタデータの抽出
- 削除データの復元
- パスワード保護ファイルへの対応
- 検索インデックスの作成
これらの処理を適切に実施することで、潜在的に関連性の高いデータに絞り込んだ上でレビュープラットフォームにアップロードすることが可能となり、後続プロセスの効率化と品質向上に寄与します。適切なProcessingは、eDiscovery全体の成功を左右する重要な基盤といえます。
3. Processingにおける代表的な処理手法
3-1. 不要なデータの排除
通常、CollectionおよびPreservationのプロセスで取得されたESIには、訴訟や調査において証拠としての価値を有しないデータが多く含まれています。代表的な例として、OSの動作に必要なシステムファイルやアプリケーションの実行ファイル、キャッシュファイルなどが挙げられます。これらの明らかに無関係なデータを排除し、次の処理段階に移さないことで、全体の処理効率を向上させることが可能になります。
米国商務省の国立標準技術研究所(NIST)は、さまざまなソフトフェアに関連する既知ファイルのデータベースである「National Software Reference Library (NSRL)」を公開しています。このデータベースを参照することにより、既知の不要ファイルを効率的に特定・排除できます。
参考:NIST「National Software Reference Library (NSRL)」、www.nist.gov/itl/ssd/software-quality-group/national-software-reference-library-nsrl(2025年7月30日アクセス)
さらに、NSRLなどを用いた既知ファイルの排除に加えて、ファイルの作成日や最終更新日、ファイルタイプといったメタデータを基準にフィルタリングを行うこともあります。
3-2. データ展開処理
ZIPやRARなどの圧縮ファイルや、PSTなどのメールアーカイブファイルといったコンテナファイル、さらにdd形式やE01形式などのディスクイメージファイルは、展開処理を行わなければ内部のファイルを確認することができません。そのため、ファイルの種類に応じて、適切なツールや手段を用いてデータを展開する必要があります。
こうした展開処理においては、コンテナファイルとその内部ファイルや添付ファイルとの「親子関係」を正確に保持することが重要です。これにより、データ間の関係性を正しく把握でき、情報の文脈や経緯をより的確に捉えることが可能となります。
3-3. 重複排除(Deduplication)
保全・収集されたESIの中には、同一のファイルが複数存在する場合があります。これらをそのままレビュー対象とすると、工数の増加によって不必要なコストが発生するだけでなく、同一ファイルに対するレビュー状況の不整合などにより、レビュー全体の一貫性が損なわれる恐れがあります。このような状況を回避するために「重複排除」が行われます。
同一性の判定には、ハッシュ関数によって算出されるハッシュ値を用います。ファイルの内容に基づいて生成されるハッシュ値は、内容が1バイトでも異なれば別の値となるため、ハッシュ値の一致によって完全に同一のファイルであると判定することが可能です。
3-4. テキストやメタデータの抽出
レビューや検索・分析に活用するためには、ファイルから本文のテキストおよびメタデータ(作成日時、作成者、ファイルパス、メールの送受信者、件名等)を抽出する必要があります。スキャンされたPDFのような画像ファイルなどについては、OCR(Optical Character Recognition/光学文字認識)技術を用いてテキストを抽出する場合もあります。
このプロセスで得られた情報は、キーワード検索やタイムライン分析に活用され、データの内容把握だけでなく背景や経緯の理解にも寄与します。
3-5. 削除データの復元
調査の内容によっては、削除されたファイルの断片や痕跡を復元し、その内容を分析する必要が生じることがあります。これにより、意図的に隠ぺいされた情報が明らかになる可能性があります。
削除されたファイルは、ファイルシステム上から見えなくなっていても、実際のデータがストレージ上に残っていることが多く、専用のツールを用いることで復元が可能となる場合があります。ただし、記憶媒体の種類やデータの上書き状況、削除からの経過時間などによって、復元の可否や精度は大きく左右されます。
3-6. パスワード保護ファイルへの対応
顧客データや機密情報を保護するため、暗号化やパスワードによるアクセス制限が広く用いられています。このような保護が施されたファイルについては、レビューや分析を可能にするため、必要に応じて復号化やパスワード解析処理を行います。
一般的な手法としては、事前に関係者から提供されたパスワードを用いる方法の他、辞書攻撃※2やブルートフォース攻撃※3などがあります。ただし、パスワード解除は強制的なアクセスを伴い、証拠性に影響を与える可能性があるため、特に法的・倫理的な配慮が必要です。また、処理の過程でデータの破損など証拠性が損なわれる事態が発生しないよう、十分に注意して実施する必要があります。
3-7. 検索インデックスの作成
最終的に、抽出されたテキストやメタデータをもとに、検索用のインデックスを作成します。これにより、後続のプロセスにおけるキーワード検索や条件に基づく絞り込みを、迅速かつ正確に行うことができます。また、新しいデータが追加された場合や古いデータが削除された場合には、インデックスの再構築や更新を行うことで、常に最新の情報に基づいた検索を実現します。
※2 辞書攻撃:パスワード候補リスト(辞書)に含まれる文字列を順に試し、一致を探索する手法です。例として、単語、人名、地名など推測されやすい候補が用いられます。
※3ブルートフォース攻撃:文字列(数字/英字/記号など)と長さを定め、考えられる組み合わせを網羅的に生成して試す手法です。組み合わせ数に応じて時間を要します。
4. チャットやメッセージファイルのProcessingについて
近年、業務ではノートパソコンに加えて、スマートフォンやタブレットを使用することが一般的です。コミュニケーションツールにおいても、メールのみならず、チャットやインスタントメッセージが日常的に利用されています。これらのチャット等のデータも、訴訟や当局調査の開示対象となり得るため、適切にProcessingを行い、後続のプロセスへとつなげる必要があります。一方で、従来のESIの処理手法(3.までで説明したProcessingにおける代表的な手法)は、主にPCやメール、サーバーデータのファイル(Office系ファイルやPDF等)を対象として発展してきたものであり、過去20年間で急速に普及してきたスマートフォンやコラボレーションソフトウェアで利用されるメッセージやチャットデータについては、従来とは異なる手法で処理しなければなりません。
メールやPDF等のファイルは、ファイル単位でレビューを行うことで内容を確認し、訴訟や調査との関連性を判断することが可能です。しかし、チャットやインスタントメッセージの場合、個々のメッセージだけでは文脈が不十分であり、訴訟や調査への関連性を判断することが難しいケースが少なくありません。そのため、例えばフォレンジックソフトウェアを用いて、1日の会話のやり取りを1つのファイルに成型するなど、会話の前後関係を把握しやすくする処理が行われます。
チャットやメッセージデータについては、「実際に会話をやり取りした形式」により近い形で表示、検索できるよう、適切な処理や工夫を施さなければならず、そのためには専用のフォレンジックソフトウェアが必要です。こうした技術力と専門性の高さが、レビューの効率性向上に寄与します。
5. まとめ
Processingは、多種多様なデータが開示対象となり得るため、対象となるデータや訴訟・調査の内容に応じて、データ処理方法や手順を工夫することが重要となります。 適切なデータ処理を行わなければ、重要な情報の見落としにつながり、結果として、訴訟や調査において必要なデータを提出できないというリスクを招く恐れがあります。
これらのリスクを回避し、効果的なデータ処理を行うためには、実務に精通した外部専門業者の支援が欠かせません。データ量がeDiscoveryのコストに大きな影響を与えることを踏まえると、不必要なコストを抑制する観点からも、外部専門業者による高品質なProcessing対応は重要です。eDiscoveryを効果的に進めるためにも、外部専門業者を選定する際には、技術力と実績という観点にも着目して検討してはいかがでしょうか。
【共同執筆者】
EY Japan Forensic & Integrity Services
布施 和弘、池上 弘樹、高尾 祥平、木村 香穂、榎本 周真
サマリー
Processingは、eDiscoveryの一連の作業の中でも重要なプロセスの1つであり、どのようなデータ処理を行うかが、eDiscovery対応の結果とコストを左右します。レビューや分析を効率的に進めるためには、Processingにおいて適切な処理能力と技術力を備えた外部専門業者の支援が不可欠であり、その活用は、eDiscovery対応全体の作業効率向上につながります。
関連記事
eDiscoveryの基本:Preservation/Collection
eDiscovery対応において、関連データを改ざんや消失から守ることは、訴訟戦略やコンプライアンスに直結する重要なポイントです。本稿では、eDiscoveryの一連の作業の中でも重要なプロセスの1つであるPreservation/Collectionについて、代表的な処理手法を紹介するとともに、そのリスクと重要性について解説します。
eDiscoveryの基本:Information GovernanceとIdentification
事業活動の礎となる情報を適切に管理することは、リスクの最適化とデータ利活用の両立を可能にし、企業価値向上の重要な基盤となります。本稿では、情報管理の枠組みの1つである情報ガバナンス(Information Governance、以下IG)の基本概念と重要性に加え、訴訟対応などの場面で不可欠となる情報の特定(Identification)について解説します。
eDiscoveryとEDRM ― 米国民事訴訟における証拠開示制度
米国をはじめとした海外の民事訴訟や当局調査への備えがないと、意図しない証拠破棄等により制裁金を科されるリスクが増大します。またそうなった場合、レピュテーションの低下を招くなど、事業活動への重大なダメージにつながる恐れがあります。本稿ではeDiscoveryの概要とプロセスについて紹介するとともに、企業の訴訟戦略における平時対応の必要性と重要性についても解説いたします。
EYの関連サービス
