






EY refers to the global organization, and may refer to one or more, of the member firms of Ernst & Young Global Limited, each of which is a separate legal entity. Ernst & Young Global Limited, a UK company limited by guarantee, does not provide services to clients.
How EY can help
-
Our Consulting approach to the adoption of AI and intelligent automation is human-centered, pragmatic, outcomes-focused and ethical.
Read more
Bootstrapping RAG with knowledge graphs
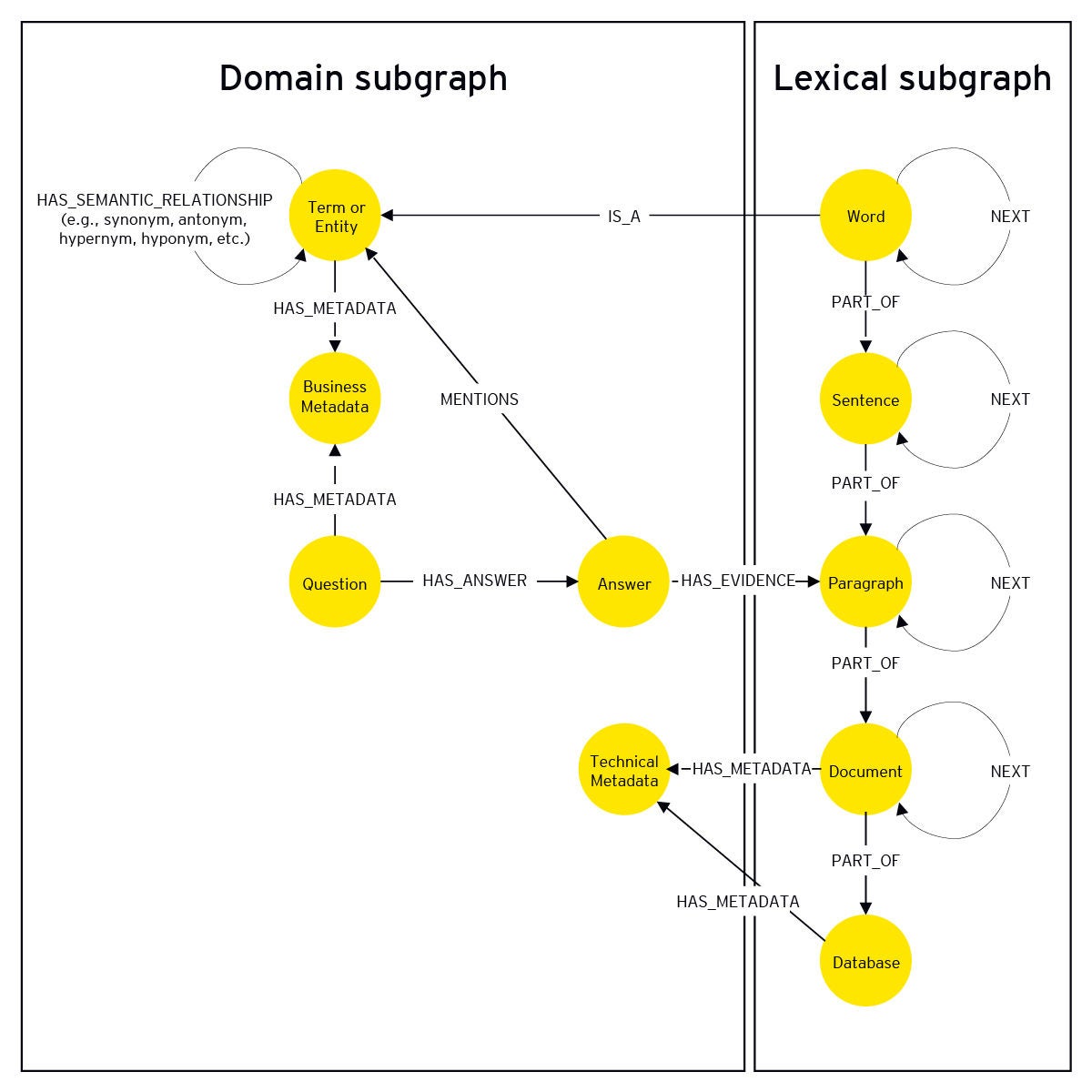
A KG is a structured way of representing how entities are interrelated. Depending on the domain, entities can be things, events or concepts, and their modeled relationships can describe equivalence, hierarchy, ownership and other associations. KGs are stored in graph databases, which are databases that are optimized for storing data with complex relationships that must be traversed at query time. KGs are useful for large organizations because they break down data silos and enable holistic understanding of operations by fusing intra- and interdomain knowledge from multiple data sources at all levels of abstraction. Since KGs support fusing, locating, contextualizing and understanding data, they represent a substantial maturity shift from unstructured text corpora being embedded and stored in a vector database for RAG applications.
As expected, a common KG-bootstrapped architecture is like traditional RAG architecture but inclusive of a graph database, data engineering pipelines that hydrate and enrich the graph, and additional orchestration and prompting to exploit the graph’s hierarchy in AI-generated responses. There are technical differences between knowledge-augmented generation (KAG) and graph RAG methods, but generally the graph database serves as the backbone of the architecture, storing entities extracted from upstream content and their relationships in a domain subgraph and, depending on the use case, document chunks from that same upstream content in a lexical subgraph. Since a domain graph describes business knowledge and a lexical graph describes linguistic structure, together they paint a rich picture of precisely where business domain knowledge exists in source content. Further, the superstructure of the graph allows broad understanding at various levels of abstraction such as summarizing across a corpus or identification of common themes within and across documents.